過去幾個月來,我自己經手的專案和玩具都已經陸陸續續升級到 Java 8 了,包含一個 8 年前的 Java 5 老古董專案。升這麼舊的專案當然花的時間就比較多了。不過過程都差不多:
- 移植到 Intellij IDE 上開發
- 換上 JDK 8
- 修正 compile 的錯誤 (很少)
- 升級任何不能在 Java8 執行的 library (Hibernate, Spring....etc)
- 執行 Unit Test -> 修復 -> 再測 -> 修復...
- 將舊的 ant/maven 換成 gradle
- 將舊的開發環境換上 Vagrant + Ansible
大部份麻煩的步驟都是在第四和第五,一旦 Unit Test 全部過關後就算大功告成啦。過去努力維護的單元測試,在這裡又發揮了關鍵的作用。我八年前寫這些測試大概沒想到還能這麼有用 (笑
Garbage 1st Garbage Collector - G1GC
好了,我已經正式佈署 JDK8 到正式線上,跑了幾個月都很穩,該來嘗試點新的功能:新的 Garbage Collector - G1GC。G1GC 早在 JDK7 就有了,不過新的 collector 要經過相當長的時間實戰和焠鍊才會成熟穩定,我想到了 8 應該已經算等很久了,正式上線實測應該沒問題。
HotSpot Garbage Collectors
先大概介紹一下不同 collector 的差別,Oracle HotSpot 包含三種 collector:
- Parallel GC
-XX:+UseParallelOldGC - CMS - Concurrent Mark Sweep GC
-XX:+UseConcMarkSweepGC - G1GC
-XX:+UseG1GC
HotSpot 預設的參數下是使用 Parallel GC (預設只有對新世代平行化,除非你下了上面的參數),我想這是最多人使用的,通常中小型 web server 都可以輕鬆勝任。直到哪天你開始發現有 OutOfMemoery,或者是 server 一段時間停頓個一兩分鐘沒回應,這時才會意識到 GC 出了問題,要開始檢討。
ParallelGC 雖然使用多個 Thread 同時進行 GC,但是它是屬於 Full GC。當 Full GC 開始時,整個 app 會停住,通稱 Stop-the-World pause (STW)。當 app 的服務量越大,產生的 garbage 也越多越快,每次的 STW 就會更久,服務的 availibility 也跟著降低。因此大型的服務通常都會改用 CMS,例如你安裝 Cassandra 資料庫,預設就是使用 CMS。
CMS 不一樣的地方是,它將舊世代的 GC 分為四個步驟,而且只在初始標記的過程中會 stop-the-world ( initial mark 和 remark 這兩個階段),其他的步驟都是用另一個 GC thread 去跑的,不會影響服務。這兩個標記的速度很快,所以只停一下下 (通常幾十 ms )。除非有異常,不然不會出現 Full GC 的情況。因此能達到 low pause 的目標。
G1GC 基本上與 CMS 的概念差不多,也是分階段標記後再收集,但是整個 heap 的分佈都大改:
- heap 被切成一塊塊同樣大小的
region區塊,預設的參數下 heap 會盡可能切成 2048 區 - 根據 heap 的總量,區塊大小約落在 1MB~32MB,必須為 2 的次方
- 每個區塊都可以扮演不同的世代 (young/survivor/old)
- G1GC 在 mark 結束後,會先回收垃圾最多的區塊,盡可能騰出最多的空間 (所以才叫 Garbage First)
- GC 後還活著的物件會被複製到新的區塊
因為每個區塊都可以扮演不同世代,所以 heap 的分配就很有彈性,如果服務中大部份的物件都是新的世代,只有少數會活很久,那大部份的區塊都會是扮演新世代,反之則是大部份都是舊世代。所以使用 G1GC時 -Xmn 這類調整新世代大小的參數就不重要了,而官方也不建議你去調整它。等一下會看到兩個實例,不同的服務類型會有不同的新舊世代分配比例。
另外,G1GC 的特徵是每次 GC 不會對所有區塊都做,而是設定了時間上限 (預設 200 ms),時間內估計能回收多少就做多少區塊,進行期間是 stop-the-world pause。所以實際線上運行時,會觀察到每幾十秒,或幾分鐘就會有一次 150~250ms 左右短暫的 pause,通常這樣的停頓是不會影響服務的。當然 200ms 這數字是可調整的,如果服務的 heap 很大(幾十GB),那麼 0.5~1秒的停頓也是很合理。
由於 G1GC 每次 GC 都會整併區塊 (很像以前硬碟的 defragement 工具),所以沒有像 CMS 那樣,heap 用久了會有破碎化的問題。heap 如果破碎了效率會變差,也騰不出大空間給大的記憶體需求,遇到這種情況時 CMS 只能放棄,改成啟動 stop-the-world Full GC,造成服務又中斷了。G1GC 的新設計克服了這個問題。
減少 GC 停頓很重要嗎?
上述的各種 Collector 中,我們可以將它們簡略分為兩種策略,一種是直接做 Full GC,停頓整個 app 一長段時間;另一種是想辦法將這長時間的停頓 切碎,讓 VM 每小段時間收集一點,而避免一次中斷太久。至於要挑哪種就要看服務的類型了,如果服務是跑 batch job 的,或是純做分析,那麼每跑完一輪做一次 Full GC 反而比較有效率。反之如果是即時的服務,例如一般的 web app,通常會選擇零碎的小停頓這種策略。
我想上述的說明應該是有經驗的 server-side 開發者都具備的基本概念。不過最近幾年趨勢有變,我們看到 NoSQL 興起,雲端主機盛行,很多服務都叢集化了,動不動就是三台以上,大型的則走到數十台以上。叢集系統有很多類型,Master-Slave,Peer to peer 之類的,但不管是哪類,它們的最大弱點就是主機間的連線斷線。在資料庫這領域裡,就是 CAP 理論中的 Partition (系統間隔離)。
Partition Caused by Long GC Pause
一般我們提到 Partition 時,通常是指某台主機掛掉,或是網路連線中斷。但是如果你的 heap 很大時,Full GC 造成數十秒以上的停頓,很多叢集系統的自動機制會誤判該主機為離線 (設定的很靈敏),然後就進行一連串的 修正 ,比方說換別台做為 Master,或是進行資料修復。原本這類型的自動機制是用來應付少量的主機掛點 (約十幾週一次),或非常少的網路斷線 (一年約一、二次吧)。但如果 GC 沒有調好,變成一天 Partition 十幾次,這真是惡夢啊!頻繁的切換造成效能低落,更造成一堆資料不一致,很傷。
GC 停頓是最高機率的 partitoin 來源
上面說到要看服務的類型來挑 collector 的策略,但叢集的趨勢使得越來越多的服務必須選擇零碎小停頓的策略,而且高效能的 collector。
G1GC in production
我手邊有兩種完全不同類型的專案,嘗試切換到 G1GC,現在收的數據還不多,不過可以看看 heap 分佈長什麼樣子。
DinBenDon: 傳統 web server
- 這是一台 16 核的 dedicate server,切換前是跑 JDK-6

- 切換後是 JDK-8u20
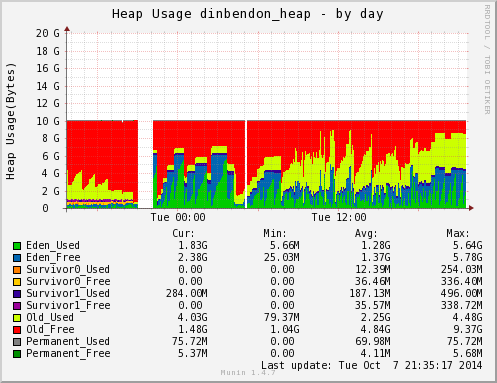
ok,這是訂便當網站,它服務的時間集中在早上到中午,我們可以看到在 9 點和 12 點間 heap 有大量的使用。我們比較這一段就好了,其他時段不重要。藍綠色是新世代 Eden_*,黃色的部份則是舊世代 Old_Used。
| DinBenDon | 第一張 | 第二張 |
|---|---|---|
| JDK | JDK 6 | JDK 8u20 |
| 參數 | -Xms10G | -Xms10G |
| -Xmx10G | -Xmx10G | |
| -Xmn1G | -XX:+UseG1GC | |
| -XX:+UseStringDeduplication | ||
| Collector | Parallel GC | G1GC |
| Full GC | 每次 1~3 seconds | none |
| GC 特徵 | 每半小時一次 Full GC,大鋸齒 | 零碎鋸齒,約幾十秒停頓 200 ms 一次 |
| 新世代比例 | 固定為設定值 1GB | 隨著服務不斷變化,在2~4GB間 |
原本使用 JDK 6 服務時,雖然有 Full GC,但我給的 heap 很大,所以大概半小時才發生一次,每次發生最多也才 3 秒 (這歸功於這台專屬的 server CPU 太強太快了)。因此服務上是沒什麼差,所以才可以服務了好幾年都沒事。
切換到 G1GC 後,沒有討人厭的 Full GC 停頓了,只剩零碎的短 GC。而且我們可以看到舊世代一直維持在 3GB 左右,變化的都是新生代,落在 2~4GB 間。這是 G1GC 隨著服務產生物件的速度一直動態調整的比例。從 G1GC 的圖來看,我以前調的 Java 6 新世代 1GB 太少了,應該可以調到 3GB 才是最佳的值。(新世代的 GC 比較有效率,所以你會想調大一點,但你也不知多大才是最好的比例,要測很多輪)。這是另一個 G1GC 的好處,你不用煩惱新舊世代的分配比例,他會自己調配。
String Deduplication
JDK8 上我除了切換到 G1GC 外,我還開了最新 8u20 才加上的 string deduplication,這是 G1GC 獨有的功能,它能將 heap 中 String 物件裡面包的 char[] 進行共用,換句話說如果 heap 中有多個 String 物件的字串值一樣,那它們配置的 char[] 只會有一份。
這個功能太新了,我上線時也是怕怕的,好在跑了一陣子沒什麼事。如果你有開 GC log ,你會看到每次 G1GC 做完 collection 後,會印出去掉的重覆 char[] 量:
GC concurrent-string-deduplication, 11.7M->344.4K(11.4M), avg 96.6%, 0.1123200 secs
去掉了重覆字串高達 95% 以上!真的這麼神嗎?!非也非也。訂便當 這個服務其實架構上很差的,它服務的尖峰期同時上線人數才三千多人,每個人最多停留 10 分鐘,卻要開到 10GB 的 heap,你就知道浪費了多少記憶體。雖然我替它升到了 Java 8,最新的 Spring,但這仍舊是八年前的架構,http session 裡放了一大堆重覆的物件。除非要砍掉重練 ( NO ~~~~! ),不然我也只能繼續餵更多 heap 給它。
也因為有大量的重覆物件在 heap,才會出現字串去重覆率 95% 這種怪現象,一般正常的 app 頂多 50% 左右就很好了。它總共省了多少 heap 我還沒仔細精算,不過大概每次 GC 就省個 10MB 左右。(從圖上來看 JDK8 的 heap 比 JDK6 的少了一些,不過這可能是 JDK8 帶來的整體改進,跟去重覆無關。)
Humongous Allocation
G1GC 除了正常的配置外,還有一種特別的配置叫 Humongous Allocation (堆積配置),這個發生在當物件使用的 heap 比 region 區塊的一半還大時。通常出現這種配置時是個警訊,你要開始手動調大 region,不然很容易出現 Full GC。訂便當這個網站大約一小時會出現一次這種配置 (有人在跑報表),但目前無傷大雅,所以使用的 region 大小仍然由 VM 自己推算 (4MB)。
Cubie Messaging Server
Cubie messaging server 是個 mega monolith server,所有用戶都會與它保持連線 (一台十幾二十萬 client 吧),並且負責線上訊息的傳遞,而且還包含了所有的 business logic,總之整個 Cubie 服務通通包在一台 server 裡。
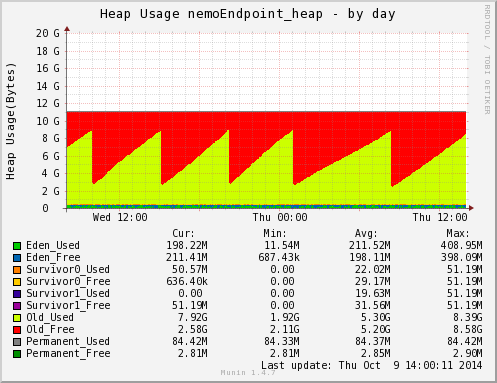
- 部署的硬體是 AWS 四核 15GB 的主機,切換前是 JDK-8u5 CMS collector
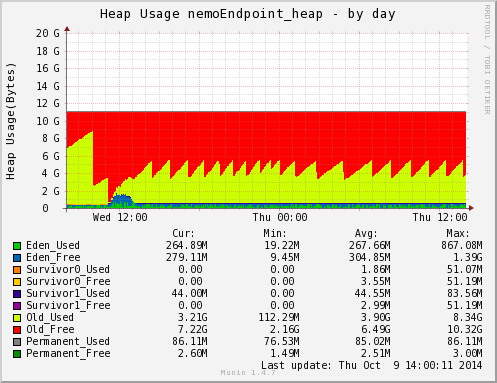
- 切換後是 JDK-8u20 G1GC
| Cubie | 第一張 | 第二張 |
|---|---|---|
| JDK | JDK 8u5 | JDK 8u20 |
| 參數 | -Xms11G | -Xms11G |
| -Xmx11G | -Xmx11G | |
| -Xmn512m | -XX:+UseG1GC | |
| -XX:+UseParNewGC | -XX:+UseStringDeduplication | |
| -XX:+UseConcMarkSweepGC | ||
| -XX:+CMSParallelRemarkEnabled | ||
| -XX:SurvivorRatio=8 | ||
| -XX:CMSInitiatingOccupancyFraction=80 | ||
| -XX:+UseCMSInitiatingOccupancyOnly | ||
| Collector | CMS collector | G1GC |
| Full GC | none | none |
| GC 特徵 | 新世代 GC 每十幾秒停頓 100ms | GC 每二十幾秒停頓 200 ms |
| 舊世代 GC 費時 20 秒 | ||
| 新世代比例 | 固定為設定值 512MB | 穩定後保持在 572 MB 左右 |
這一次的比較就都是 JDK8 互比了,只是不同的參數。第一張圖是 CMS,CMS 的參數有很多要調整,才不會出現 Full GC (目前調整的參數能完全避免)。圖中你可以看到很大的鋸齒,但那些劇降不是 Full GC,只是 CMS 舊世代的 GC,大約六小時會發動一次。執行的時間大概 20 秒。
第二張圖是 G1GC,這一次新世代配置的量就很穩定了,跟訂便當網站差很多。推敲起來應該是 Cubie 服務產生的物件沒這麼多,這麼快 (訊息都很短),而舊世代的 heap 量也都一直很穩定,那些 heap 都是連上線的人佔據的 (一台大概十幾二十萬人)。messenger app 連線是不間斷的,所以 heap 量一直很固定。
採用 G1GC 的結果顯示了它不需要繁複的調整,也能達到短暫停頓的目標 (200ms)。圖中舊世代累積到 5 GB 左右時就開始 mixed GC 了 (混合 GC 是指新舊世代一起收集,G1GC 獨有),這是因為預設觸發的比例是達到總 heap 45% 就開始進行。未來我應該會把它再調高一點吧。
這個 server 現在設定的 heap 過大了,處於 under load 的狀態,通常這時候可以減少總 server 數了。 不過,Cubie server 時常會有一兩台關掉 (rolling upgrade),這時其他台人數會瞬間增加很多,所以會預留多一點 capacity。
至於 String 去重覆率,這一次 Cubie Server 的值就比較正常了,大概落在 45% 左右。但感覺起來沒什麼用,因為服務裡字串並沒有很多,大部份是 binary array。
結語
本文大概簡介了一下 G1GC 的特徵與功能,網路上有更多完整的文件說明它的來龍去脈,以及調校時的注意事項,比方說遇到 Humongous Allocation 時該怎麼辦等等,建議有興趣的人去讀讀。除此之外,也展示線上服務在切換不同 collector 的簡單比較。G1GC 實測的結果還不錯,不用去特別的調整就能符合原先的目標。我們也看到 G1GC 在新舊比例自動分配上,不同的服務類型會有相當大的差異。當然如果要比的更詳細就要算 GC 的 throughput 了,這要多收集點資料才能精算,之後再說吧。
Oracle 官方不會因為有 G1GC 就拿掉 CMS,但長程的計畫是要 G1GC 成為主推的方案。我們現在有三種 collector 可以挑選,經過這次實測後,我想未來我會優先採用 G1GC,畢竟很多調整都自動化了,也解決了破碎化的問題。